

What Should AI Remember About You?
ChatGPT revises its memory of you now, on its own.

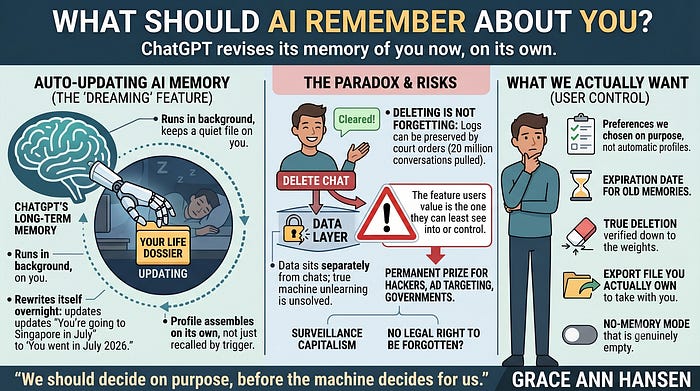
On June 4, OpenAI shipped a feature called Dreaming. It lets ChatGPT update what it remembers about you without being asked, and revise those memories on its own as your life moves. The company that built the fastest-growing app in history now runs a quiet background process whose job is to keep a current file on you.
The headline that week said something else. ChatGPT has surpassed a billion users, making it the fastest app ever to reach that milestone. The number is real enough, but it is not OpenAI’s number. It comes from Sensor Tower, a market intelligence firm, via Reuters, and it counts monthly active app users. OpenAI’s own most recent figure, from February, was 900 million weekly active users. Both can be true at once. The distinction matters. A company that is careful about which metric it claims is a company you should read just as carefully when it tells you what its memory feature does.
So let me tell you what it does, and why the cheering around it should make the back of your neck prickle.
The people building it think memory is the whole point.
Sam Altman has been describing the destination for a long time. At a Sequoia event last spring, he laid it out: he wants a model where every conversation, every book, every email, everything you’ve ever looked at is loaded in, and, in his words, “your life just keeps appending to the context.” He’s noted that younger users already treat ChatGPT like a life advisor and don’t make decisions without it. Dreaming is a step toward that model. OpenAI’s own framing is plainer. Memory, the company says, is central to “knowing you, helping you, and doing more for you.”
The competitors are building the same thing in different ways. Google folded memory into Gemini. Anthropic shipped it to everyone in March and even let people import their history from ChatGPT and Gemini, and described its version, at least at first, as a recall you trigger rather than a profile it assembles on its own. The contrast is the interesting part. Two companies looked at the same feature and made opposite bets about how much of the remembering should happen behind your back. OpenAI bet on automation. Dreaming runs when you’re not looking, and it rewrites itself: the system’s own example is quietly updating “You’re going to Singapore in July” to “You went to Singapore in July 2026” once the trip is over.
Anthropic’s product chief, Mike Krieger, has pitched memory as the road to “sustained thinking partnerships” that evolve over months. That is the case in its best clothes. Not a dossier, a relationship. And on a good day, it feels like one. The model that remembers your project, your deadline, the argument you were building last Tuesday is genuinely more useful than the amnesiac that greeted you fresh every single time. Nobody is wrong about the convenience. The fight is over the price.
The people who study this for a living are less charmed. A 2026 study presented at the field’s main human-computer interaction conference looked at how people actually live with ChatGPT’s memory and found a paradox. The feature most users value is the one they can least see into or control. You like that it knows you. You cannot view the whole of what it knows, and you cannot be sure you’ve deleted any of it. OpenAI says its newest memory recalls facts about you far more accurately than last year’s version did, and I believe the trend. But those scores are the company grading its own homework. No independent audit of the new system existed the week it launched. You are being asked to trust a black box about how faithfully it keeps a copy of you.
That last part is not a feeling. It is a technical fact, and it is where the cheering stops.
How it haunts us
This is the part that should change how you use the thing.
The feature is not evil. The architecture around it is built to keep, and keeping is the opposite of forgetting; you have quietly relied on it your whole life.
When you delete a ChatGPT conversation, you have not necessarily deleted it. We know for a fact that a federal court made OpenAI prove it. In the consolidated copyright case brought by The New York Times and other publishers, a magistrate judge ordered OpenAI in May 2025 to preserve and segregate output logs that would otherwise be erased, including chats users had asked to delete. The order was later narrowed. The court still required OpenAI to hand over 20 million de-identified user conversations to the other side, and in January, a district judge affirmed the order, reasoning in part that users had “voluntarily submitted” their messages when they typed them.
Read the mechanics of that twice. Your delete button cleared your screen. It did not clear the record. A court reached past your deletion, past OpenAI’s own retention policy, and pulled twenty million conversations into a lawsuit, on the logic that you gave them away the moment you hit enter.
Now layer a memory system on top, one whose job is to keep a living profile of you, and the problem compounds. Deleting a memory in the settings page is not the same as the model forgetting. OpenAI’s own help pages admit it: saved memories sit separately from your chats, so deleting a chat does not delete what was learned from it, and scrubbing one detail can mean chasing it through every place it appears. Go down to the training layer, and forgetting becomes nearly impossible. Researchers call the field “machine unlearning,” and the honest summary is that nobody has solved the problem of proving a model has truly forgotten a specific person. A 2018 paper put the whole conflict in its title: humans forget, machines remember. Its authors concluded it may be impossible to honor the legal right to be forgotten inside an AI system at all.
That right is not hypothetical. Article 17 of Europe’s data law gives you the right to have your personal data erased. A statute can command erasure. It cannot make a neural network obey the laws of physics.
And do not count on regulators to close the gap. Italy’s privacy authority fined OpenAI fifteen million euros in 2024 over how it handled personal data. This spring, a Rome court threw out the fine, not on the merits but on a jurisdictional technicality, and pointedly declined to rule on whether the privacy violations had actually occurred. The substance is still undecided. The enforcement evaporated anyway.
Put the pieces together, and a grim sentence assembles itself. The data outlives the conversation; the model cannot cleanly forget; the regulator’s fine was vacated on a technicality; and a court has already shown it can pull the logs. One commentator summed up the era in a headline: the right to be forgotten is dead, and data lives forever in AI. That is too tidy to be the whole truth. It is not too tidy to be a warning.
Memory is a target. Security researchers have already shown that a poisoned web page or document can write hidden instructions into ChatGPT’s long-term memory, causing them to persist across every future conversation and quietly forward what you say to a stranger. OpenAI patched that specific exploit. The category does not patch. A permanent store of your private context is a permanent prize for anyone who wants it, whether a hacker, a divorce lawyer, an immigration officer, or a future government that decides your old questions are evidence.
There is a quieter use than the breach, and it asks no one to break in. The company already holds the record, and it has begun testing what to do with it. OpenAI has trialed ads inside ChatGPT, personalized based on a person’s own chats and memories. Hold that next to Altman’s line about your life appending to the context, and the business model snaps into focus. A system that knows what you fear and what you are ashamed of is a system that can sell to you, or sell you, with a precision no billboard ever managed. Profiling was always the destination. Memory is the part where it gets good at it.
The shape of it is familiar.
Step back, and you have seen this before. Shoshana Zuboff named it surveillance capitalism: a business that treats your lived experience as free raw material, converts it into data, and builds an asymmetry of knowledge and power from that data, which she called unprecedented in the human story. Persistent AI memory is that logic finishing its sentence. The inference machine used to guess at a demographic. Now it remembers your name across the years and revises the file as you sleep.
I have spent a lot of words on who gets to hold a person’s record. When my state moved to expand its surveillance of trans residents, I wrote in “The Anatomy of Erasure” and “Seal the Records” about why a government’s permanent file on a class of people is a weapon and not a filing cabinet. The corporate version is not gentler. It is worse in one specific way. The state needs a subpoena to access a company’s records about you, and, as the OpenAI case just demonstrated, the subpoena works.
I keep finding the same pattern when I write about this. A record gets built for one stated reason, and then the reason quietly widens. The list meant to protect becomes the list used to find. It takes no villain. It takes a database, a new administration, and a definition of threat that grew as no one reread the fine print. An auto-updating memory is that fine print, rewriting itself overnight, on a server you do not own.
What we actually want it to remember
So what do we want it to remember?
Not nothing. The appeal is real. A tool that remembers that you take your notes in metric, that your kid’s name is Sam, and that you don’t have to reintroduce him every single morning saves the small daily tax of having to start from scratch. That is worth having.
What we want is the memory we chose. We want it to hold the preferences we hand it on purpose and to let the rest go. We want an expiration date. We want to carry it with us when we leave, the way Anthropic’s import tool gestures at, and we want leaving to be real, deletion that reaches the model and not just the screen. We want a mode where the thing simply does not remember, and we want to trust that the mode is telling the truth.
None of this is utopian. Time decay of old memories, an export file you actually own, a no-memory mode that is genuinely empty, deletion verified down to the weights: these are engineering problems, not laws of nature. The companies have not been pushed to prioritize them. The version that remembers everything wins the demo.
Altman, to his credit, has floated one piece of this. He has argued for what he calls AI privilege, a legal shield around your conversations with a model, similar to the one around what you tell a lawyer or a doctor. It does not exist yet. It is worth building. But privilege protects the conversation. It does not answer the harder question, which is whether a machine should be assembling a version of you that you never sat down to write, that edits itself overnight, and that outlives your decision to be done with it.
The teenager typing the questions she cannot ask anyone else is not building a profile. She thinks she is having a conversation. The distance between those two things is the entire problem. We get to decide, with the defaults still soft and the laws still being drafted, whether the most intimate record ever kept of ordinary people belongs to the people inside it.
We should decide on purpose. The machine is already deciding for us, every night, in its sleep.
Author Note. Grace Ann Hansen is an independent researcher and writer, and an MBA & PhD graduate student in health informatics and artificial intelligence. She is also a published author, a professional musician, a gymnastics coach, and a queer transgender woman living in Sioux Falls, South Dakota. All interpretation, argument, and prose are her own. Correspondence concerning this article should be addressed to Grace Ann Hansen at grace@graceannhansen.com.